Housekeeping Best Practices
Introduction
An automation solution requires a fast, clean, and stable environment - in other words, a healthy environment. And for an environment to stay healthy, housekeeping must be done.
Housekeeping is not always a priority for end users, because they may not realize the organizational and technical need for it. Customers with an on-premises installation of RunMyJobs can mitigate technical performance problems encountered by adding additional components, such as CPUs, memory, or storage on the database and/or central server. However, this only hides any possible issues and can cause extra risk at moments where prompt action (for example, to restore the system) is required.
Customers who benefit from the Redwood SaaS solution always have a healthy environment, and will be warned when the Cloud Services team notices anomalies that need to be addressed. This enbles Redwood to guarantee that the environment will be healthy, stable, and performant.
This topic covers proper housekeeping and, where required, the implementation of an archiving solution.
Key Considerations
There is more to housekeeping and archiving than just deciding how long you want to keep your data. The following considerations should be taken into account when looking at housekeeping and archiving requirements.
-
Why: Why do you want to keep and archive data? Make sure you understand your company policy. You might not be required or even allowed to retain data for a specific period.
-
What: RunMyJobs does not store customer data, but it generates a lot of execution metadata. Do you need all of it, or do you only care about processes that fail? Keep in mind that customer data must be archived on customer systems, not from within RunMyJobs.
-
Where: Your archive location should be safe, maintained, and available. Will data be stored on-site or at a different location? Follow your company standard.
-
When: How often do you need to access archived data? Is the archive intended for regular viewing, or should it only be restored when required?
The Full Picture
The image below shows the lifecycle of execution data. From left to right:
- Process Execution: Execution data is stored in Redwood.
- Data Available in Redwood (Cloud): The execution data is available in the cloud. RunMyJobs stays clean, fast and stable by following retention rules (keep clauses). Any data that must be kept longer can be archived in a customer's archiving system before a data purge (for example, using Redwood Reports).
- Data Purge: Redwood's standard housekeeping cleans up the execution data based on the defined retention.
- Data Available in Customer's Archiving System: The customer will have the data in their archiving system available for long-term auditing.
- Archive deletion: Even archiving systems will, in most cases, have retention and must be periodically cleaned up. This task can also be automated.

Generated Data
Objects in RunMyJobs generate data which is saved on the central server. Depending on the process type, the output can also be saved on the Platform Agent for OS jobs or on the spool host, which is also a Platform Agent assigned to store data from ERP jobs.
Execution Data
Each process generates output and log files for each execution. This includes but is not always limited to:
- The Redwood log file
- An entry in Redwood history
- A potential log from an automated application
To put this in context, here are some examples of frequency and number of executions over a period of time if you do not set retention.
Note: These are single executions. If you have a Chain with three processes you have to multiply this number by at least three. A Chain is a process, as well as each of the Steps in the process, so a Chain of three Steps with one process in each Step generates seven processes in the Redwood repository*.
- A single process that runs every 5 minutes generates 288 daily, 2.016 weekly, about 8.640 monthly, and 105.120 yearly runs.
- A single process that runs every 15 minutes generates 96 daily, 672 weekly, about 2.880 monthly, and 35.040 yearly runs.
- A single process that runs 8 times a day during business hours generates 8 daily, 56 weekly, about 240 monthly, and 2.920 yearly runs.
- A single process that runs weekly generates 1 weekly, 4-5 monthly, and 52 yearly runs.
Looking at the more frequent processes the size of log (output of the script or application) will add up in the actual size of the total data, it shows the importance of thinking about retention. For example, keeping just the last five (completed) runs is enough for a process that runs every five minutes.
Static Data
Besides the execution data there is more data to archive. Not setting retention can impact performance in extreme cases over time, but more importantly the size of the database can impact recovery time in case of a disaster, which should be kept low in a 24/7 automation environment.
Examples of static data:
- Events: Used in processes but might have a different retention and therefore are seen as static data. Each time an event is raised an event object is created in the Redwood repository. This event history needs to be cleaned on a regular basis.
- Operator Messages
- Audits of all actions done by users
- Each Process Server writes logging information in its trace files, which are maintained and rotated automatically by default.
Retention: Top to Bottom
There are several levels of retention (keep clauses) you can set. This section explains the highest retention level you can set to more detailed retention per object, or even status-specific retention levels.
Every Redwood administrator and developer should be aware of all of the retention types, especially System_Defaults_System, which is the minimum retention every customer should set at the start of their implementation.
System_Defaults_System
This Process Definition defines a few types of defaults that are system-wide and cannot be submitted. It is possible that your system does not have this Process Definition, in which case you can create it in the GLOBAL Partition (it does not matter which Definition Type you pick when creating it). Redwood will then automatically recognize it and change the settings after you click Save & Close.
When creating or updating System_Defaults_System you are only able to set the Name, Description, Documentation, Restart Behavior, Retention, and Security settings. This section will focus on the global retention settings, which means process execution details such as logs and process monitor entries will be kept for the period of time specified in System_Defaults_System.
Best Practice: System_Defaults_System
Redwood suggests always setting the retention in System_Defaults_System as this will avoid unlimited retention in case the Retention tab is not configured when a Process Definition is created.
As a base, set 32 days in the Keep clause as shown below, which ensures one month +1 day of retention. This is applicable to all statuses.
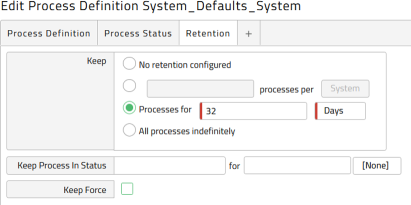
Note: The System_Defaults_System Process Definition does not exist by default. You must create it.
Tip: Any fine-tuned retention can then be managed on the specific Process Definition level. Setting this system retention does not mean other retention limits should not be set, the more frequent the process the shorter the retention period should be.
System_Defaults_Partition
You can create a Partition-specific default Process Definition which must be called System_Defaults_Partition and must be placed in the Partition you want for these defaults. This will set Partition-wide defaults and overwrites the system-wide defaults.
Best Practice: System_Defaults_Partition
When you have a Partition with a lot of processes that run multiple times per day, you can create the System_Defaults_Partition Process Definition. Figure 3 shows this for the Partition EUROPE. Click Save & Close after writing the name, and then set the retention. Figure 4 shows the default retention limit set to 8 days for this Partition.
If, for example, you have one Partition where you run Month End Close processes that run monthly, and you want to look back a bit longer, you can set the retention to 6 months. Processes that run more frequently should have shorter retention periods set.
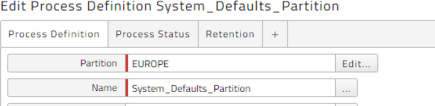
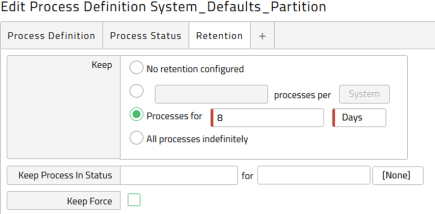
Note: The System_Defaults_Partition Process Definition does not exist by default. You must create it.
Tip: Any fine-tuned retention can then be managed on the specific Process Definition level. Setting Partition-wide retention does not mean other retention limits should not be set, the more frequent the process the shorter the retention period should be.
Chain and Process Definition Retention
When a new Chain or Process Definition is created confirm the retention you want to use by asking the following questions:
- Is the system-wide retention okay according to the defined standards for its frequency?
- Is the Partition-wide retention okay according to the defined standards for its frequency?
- Is there a Chain on the top-level where you will set retention?
If none of these options apply you MUST check the Retention tab in your Process Definition and fill in the details.
Chain-in-Chain and Process Definitions: The highest-level Chain defines the retention of all sub processes and Chains. This means you should have No retention configured as long as you configure retention in the Chain where this process runs.
Note: By default, the top-level retention is leading.
If you check Keep Force in the Retention tab, the following behavior can happen:
- If the sub-process has lower retention, the Chain will display but you might miss executions that were already purged.
- If the sub-processes have a higher retention, they will stay visible for a longer period but you will not see any relation to the top Chain.
The best practices below show different example configurations that you can use.
Best Practice: Set Retention on the Highest Level
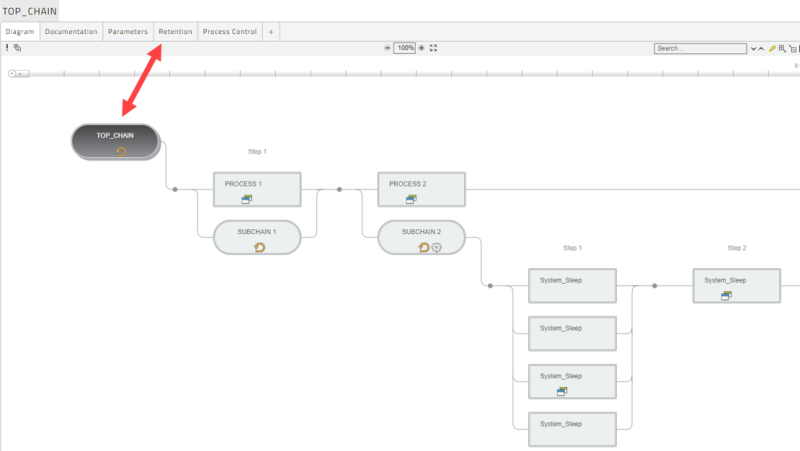
The image below shows a Chain with Processes and several sub-Chains. Setting the retention on the TOP_CHAIN applies that retention to all underlying Chains and Process Definitions.
Best Practice: Frequent Processes - Every 15 Minutes
You might need to schedule a process very frequently, for example every 15 minutes. In these situations, ascertain whether the process can be event-based. For example, triggered via a file event (which offers the needed configuration) or triggered via Web Service. If both are not an option, then ensure you configure the retention as shown below.
As a base rule, you can set the retention for frequently run processes to only keep the last 100 executions as shown in Figure 6. If you start to run many of these processes (50 or more) consider lowering this number to keep only 10 executions.
If you want to be able to troubleshoot, there is the option to keep Error statuses. Figure 7 shows a scenario wherein completed processes are not kept but errors are kept using the Keep Process in Status code E. This is helpful if you want to be able to trace processes in a certain status for a longer period of time than the standard status in order to troubleshoot, find a trend, and so forth.
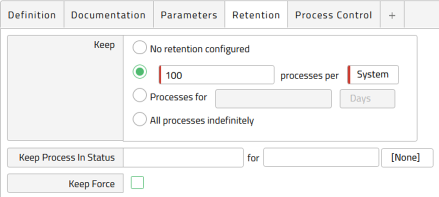
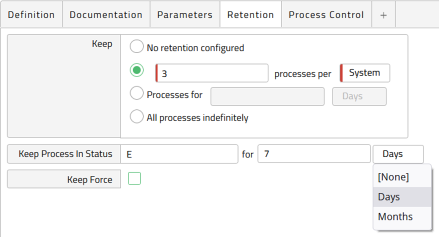
Note: Keep Process In Status means these statuses will be kept and not automatically deleted. Ensure you specify a keep duration, delete the processes manually or create a script to delete them.
Tip: Changing System (the default) to User or Key can increase the number of processes to be kept per execution context. This should be kept to system unless you need to fine-tune this further per User or Key (parameter execution context).
Example Retention
This section gives an overview of common and best-practice retention configurations when you are developing processes.
Note: Data older than 3 months should only be in your archive and not in the Redwood Platform anymore, even with lower frequent processes.
The table below provides some examples and housekeeping rules to use as a guideline. The table shows an ideal retention based on the above 3-month statement and general usage, and a best practice retention that will be workable in almost all environments.
| Process or Chain Frequency | Ideal Retention | Best Practice Retention |
|---|---|---|
| Monthly | 3 months | 12 months |
| Weekly | 3 months | 6 months |
| Multiple times per week (less than daily) | 3 months | 3 months |
| Daily | 8 days(1) | 1 month |
| 2 runs per day | 8 days(1) | 1 month |
| 8 runs per day | 8 days(1) | 8 days(1) |
| Hourly or less | Last 25 executions | Last 100 executions |
Note: (1) Using the Keep Process in Status to keep error processes for longer.
Reviewing Retention Settings
Redwood allows you to review the retention settings of all your processes by going to Definitions > Retention.
Currently it will also state No retention configured when you set the retention on a Chain level. This is because Redwood cannot be sure you submit this process outside of the Chain.
You can use the code below to run a RedwoodScript Process Definition; this will do an additional check on the retention of parent Chains. This list should be a lot smaller and can be used to review retention on your environment. It does assume you run all processes without retention configuration in Chains where retention is set.
It is normal that you will still see System_ and SAP_ Process Definitions in this list which are either templates or configuration objects.
{
String query = "select jd.* from JobDefinition jd where (jd.UniqueId = jd.MasterJobDefinition) and (jd.KeepUnits is StringNull) order by jd.Partition, jd.Name";
for (Iterator it = jcsSession.executeObjectQuery(query, null); it.hasNext();)
{
JobDefinition jd = (JobDefinition)it.next();
if (!parentHasRetention(jd))
{
jcsOut.println(jd.getPartition().getName() + "." + jd.getName());
}
}
}
boolean parentHasRetention(JobDefinition jd)
{
boolean result = false;
String query = "select jcc.* from JobChainCall jcc where (jcc.JobDefinition = ?)";
for (Iterator it = jcsSession.executeObjectQuery(query, new Object [] {jd.getUniqueId()}); it.hasNext();)
{
JobChainCall jcc = (JobChainCall)it.next();
if (jcc.getJobChainStep().getJobChain().getJobDefinition().getKeepUnits() != null)
{
result = true;
break;
}
else
{
result = parentHasRetention(jcc.getJobChainStep().getJobChain().getJobDefinition());
if (result)
{
break;
}
}
}
return result;
}Automated Cleanup
Setting the retention is the first Step, after that, retention needs to be maintained. To remove old processes and their corresponding files, there are two housekeeping processes that are scheduled with an interval of 15 minutes by default, which should be enough for most systems.
Default housekeeping Process Definitions:
- System_ProcessKeepClause: Calculates the keep clauses for jobs to determine if a job must be deleted.
- System_DeleteJobFiles: Deletes the output and log files of deleted jobs.

Figure 8: Background standard housekeeping
When your system is very busy and one or more of the above jobs runs for too long or uses too many system resources, consider scheduling these jobs less frequently or at specific times.
Changing the repetition of these jobs can have the following consequences:
- Keep clauses will be honored late. The more you widen the interval the more the disk space and overall performance can be affected.
- The total amount of disk space used by jobs for output and logs at peak times will increase. Since the output is deleted later, files will accumulate.
Best Practice: Automated Cleanup
- Leave these housekeeping processes to run with the default settings.
- Configure alerts on these processes to make sure you are warned when they fail.
- Only fine-tune the scheduling of these processes if you notice it is running too long (10-15 minutes) and you have adapted all retention correctly already.
Note: Redwood release 9.2.6 and has a housekeeping dashboard that will help monitor these processes and keep your housekeeping and retention correct.
Clean up Forgotten Processes
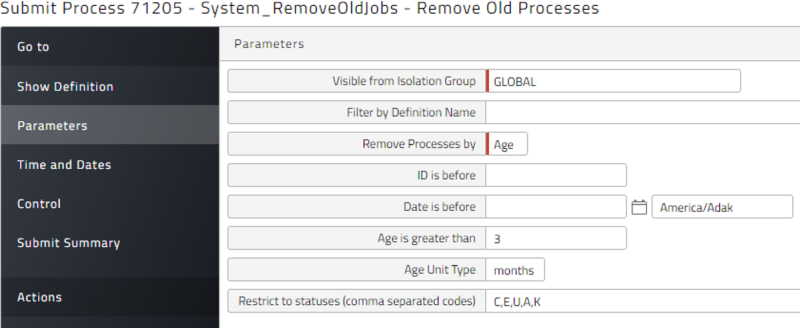
In case you have a very complex and/or old environment with execution data that is not purged for any reason (missing or complex retention configuration) there is the option to run System_RemoveOldJobs.
However, if you forgot something or if processes are stuck in a status that does not get automatically purged, to remove them you can run the System_RemoveOldJobs process. Figure 9 shows the retention age set to 3 months.
This process can also be used to purge a system which has not had proper housekeeping for a long time. Clean up in steps using the provided filters.
Include System_RemoveOldJobs in the housekeeping Chain explained in the next section.
Job History: On Premise Customers Only
The system will keep a light form of process execution history for 365 days in the HistoryJob table, by default. When upgrading the Redwood Server, the System_Upgrade process will process the HistoryJob table. This can take a long time on busy systems.
This setting can be modified by creating the following registry entry in Configuration > Registry: /configuration/history/jobhistory
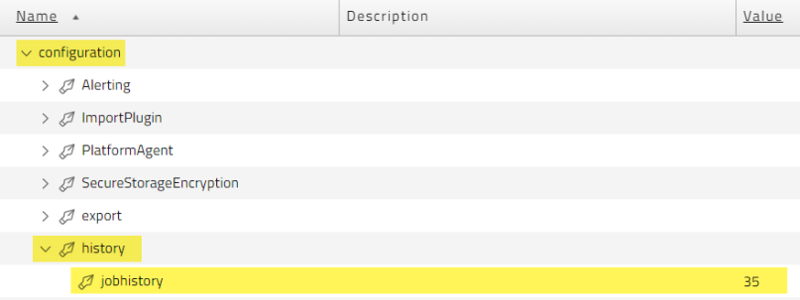
The registry entry should be set to the number of days of process history you want to keep, note that this is independent of Keep clauses. On heavily-used systems with many processes and/or Operator Messages, the HistoryJob table can grow very large.
Redwood recommends setting this registry to a minimum of 35 days (never lower), this will make the System_Upgrade process faster but will still allow you to run reports against it. This should be done gradually on heavily-used systems to ensure current processes are not impacted.
Tip: You can always gradually lower the job history to a minimum of 35 days. Even for smaller environments.
Note: The HistoryJob table can be used to report on all processes that have been executed. Deleting a process does not remove the entry from the HistoryJob table.
Note: For SaaS customers, the HistoryJob table stores only ten days of data.
Retention and Housekeeping on Static Data
Besides the processes running in the Redwood suite of products, there are also different types of static data that should be maintained to keep a healthy, fast and stable environment. These processes should then be scheduled on a daily basis, either individually or in a Chain as shown on Figure 11.
Best Practice: Daily Static Data
Create a Chain that will run your daily static data housekeeping.

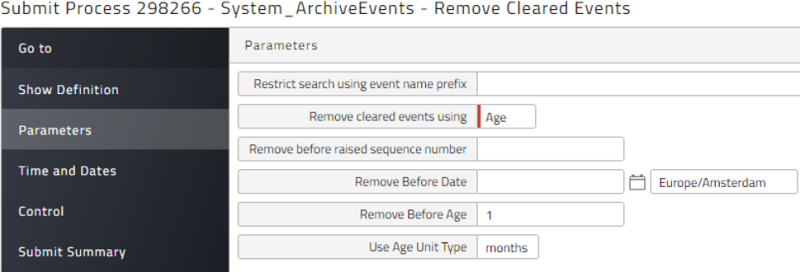
Cleared Events
Keeping all cleared events will eventually fill up the event table of your database and impact the performance of the Redwood Server. Redwood recommends scheduling System_ArchiveEvents once per day.
Best Practice: Events
Keep one month of events (maximum 10,000 events or 3 months, depending on frequency) as shown below and schedule this process to run on a daily basis.
Operator Messages
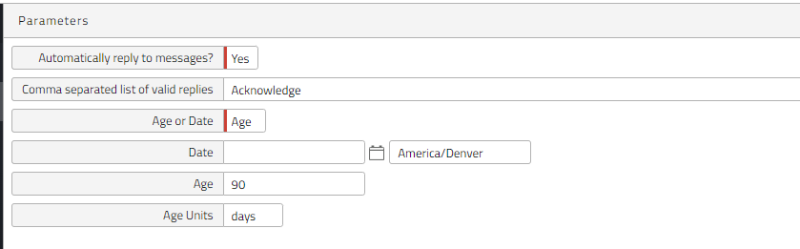
Operator Messages can accumulate over time, especially if they are heavily used. For example, an Operator Message is generated automatically whenever a Process fails. Having too many Operator Messages can slow down your system. To avoid this, Redwood recommends scheduling System_RemoveOperatorMessages to run every day. You can use this Process Definition to remove Operator Messages by age or date.
The first Parameter is Automatically reply to messages? If this is set to No, Operator Messages that are waiting for replies are not deleted, and can accumulate over time. To see how many unreplied-to Operator Messages are present, navigate to Monitoring > Operator Messages and choose All Operator Messages Awaiting a Reply from the dropdown list at the top. If there are too many, set Automatically reply to messages? to Yes when you submit System_RemoveOperatorMessages. The Process will try to reply to any Operator Messages that (a) require a reply, and (b) have a previous reply that matches one if the options in its reply list.
Note: If you set Age or Date to Age, but you do not specify values for Age or Age Units, the process will use Age = 3 months.
Best Practice: Operator Messages
Keep one month of Operator Messages (maximum 3 months) as shown blow and schedule the process to run daily.
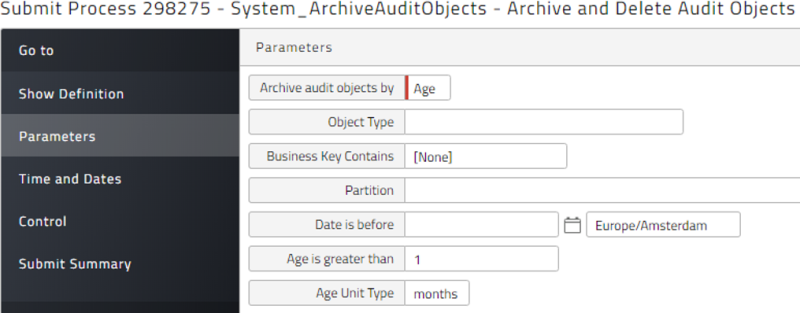
Audit Records
Audit records accumulate over time and can slow down the system. Consequently, Redwood recommends scheduling System_ArchiveAuditObjects to run on a daily basis. This Process Definition will export audit data in XML format and then delete it. You can also run System_ExportAuditObjects if you just want to view the audit records in XML format.
Best Practice: Audit Data
Keep one month of audit data (maximum of 3 months) as shown below and schedule the process to run daily.
Advanced Housekeeping
This section describes additional advanced ways of keeping your environment clean. It contains example queries you can run in your reports.
Tip: Define the needed reports and schedule them in a bi-weekly Chain to make you aware of possible enhancements.
The future housekeeping dashboard will incorporate part of these housekeeping tasks.
Show Unused Objects
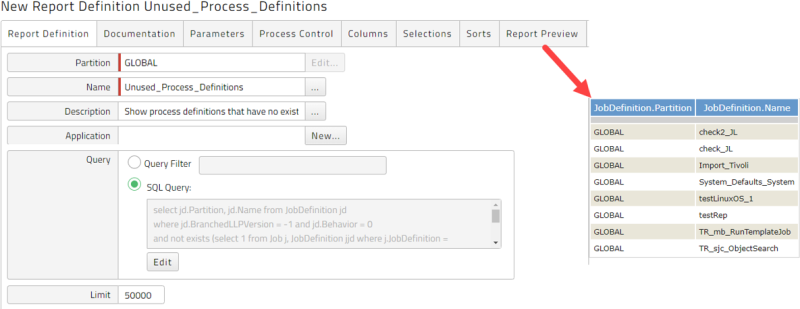
Unused Process Definitions
The following query shows Process Definitions that have no existing process execution, process schedule and are not referenced by a Chain.
select jd.Partition, jd.Name from JobDefinition jd
where jd.BranchedLLPVersion = -1 and jd.Behavior = 0
and not exists (select 1 from Job j, JobDefinition jjd where j.JobDefinition = jjd.UniqueId
and jjd.MasterJobDefinition = jd.UniqueId)
and not exists (select 1 from JobChainCall jcc, JobDefinition ljd where jcc.JobDefinition = ljd.UniqueId
and ljd.MasterJobDefinition = jd.UniqueId)
Inactive Process History
The Inactive Process History report shows processes that are not active but are expected to be cleaned up by process keep clauses.
select jd.Partition, jd.Name from JobDefinition jd
where jd.BranchedLLPVersion = -1 and jd.Behavior = 0 and jd.KeepAmount is not null and KeepUnits = 'J'
and not exists (select 1 from Job j, JobDefinition jjd where j.ParentJob is null and j.JobDefinition = jjd.UniqueId
and jjd.MasterJobDefinition = jd.UniqueId
and j.Status in ('S','R','W','O','a','q','V','I','N','8','6','Q','B','o','c','G','4','H','-'))