Data Retention Defaults
There are several levels of retention (Keep Clauses) you can set, from the general System_Defaults_System Job Definition (which lets you configure global settings) all the way down to retention per object or status. It's important to remember these settings, especially when working with Workflow Definitions.
System_Defaults_System
At minimum, every customer should create a System_Defaults_System Job Definition at the beginning of their implementation. Doing so will help you avoid creating Job Definitions that are configured for unlimited retention.
Note: The Type you specify for this Job Definition does not matter. You could, for example, set Type to Redwood Scripting Language and enter open and closing curly brackets in the Source field.
This Job Definition cannot be submitted, but simply creating it sets a few system-wide defaults. If your RunMyJobs instance does not have this definition, create it in the GLOBAL Partition. RunMyJobs will automatically recognize it and change the settings after you click Save & Close.
Note: When creating or updating System_Defaults_System you are only able to set the Name, Description, Documentation, restart behavior, Retention, and Security settings.
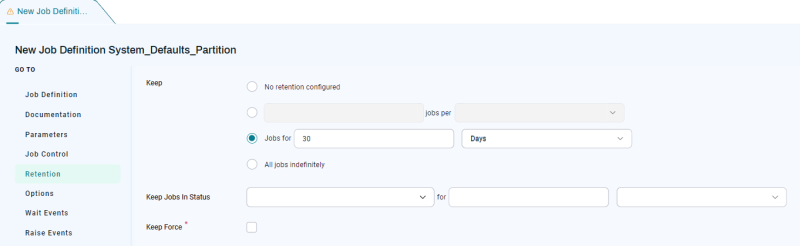
As a base, Redwood recommends setting the Keep Clause to 32 days, which ensures one month +1 day of retention. This is applicable to all statuses.
Note: Setting this system retention does not mean other retention limits should not be set. After you set up System_Defaults_System, you will most likely need to fine-tune retention at the Job Definition level.
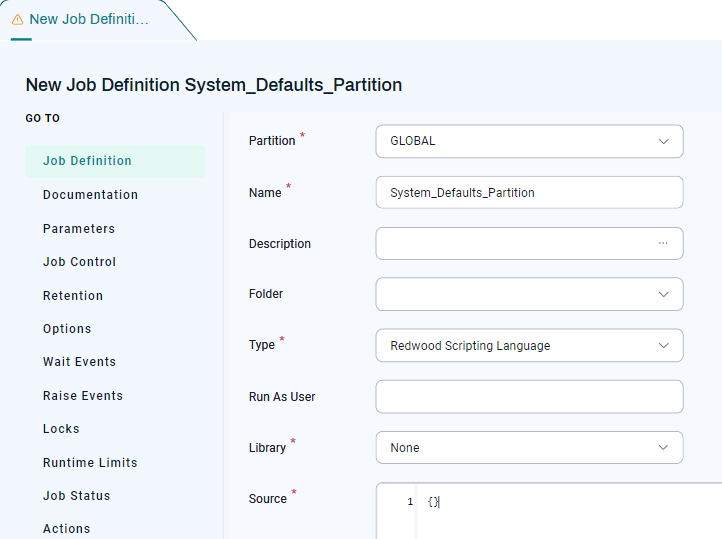
System_Defaults_Partition
The System_Defaults_Partition Job Definition lets you set default retention at the Partition level. This can be useful if you have a Partition with a lot of processes that run multiple times a day.
Note: Partition-level retention defaults override system-level retention defaults.
This Job Definition works the same way as System_Defaults_System: Simply create a new Job Definition with this name and set its defaults.
Note: The Type you specify for this Job Definition does not matter. You could, for example, set Type to Redwood Scripting Language and enter open and closing curly brackets in the Source field.
For example, assume the GLOBAL Partition contains Month End Close processes that run monthly, and assume that you want to be able to retain those processes for six months, regardless of the System_Defaults_System setting. You can do this by configuring the System_Defaults_Partition Job Definition as follows.
Workflow and Job Definition Retention
Generally speaking, the more frequently a Job runs, the shorter its retention period should be. When you create a new Job or Workflow Definition, confirm the retention you want to use for it by asking the following questions:
- Is the system-wide retention okay according to the defined standards for its frequency?
- Is the Partition-wide retention okay according to the defined standards for its frequency?
- Is there a Workflow on the top level where you will set retention?
If none of these options apply, Redwood strongly recommends that you configure the Retention tab for the Job or Workflow Definition.
When a Workflow Definition is used inside of another Workflow Definition, the highest-level Workflow determines the retention of everything in the Workflow Definition. Consequently, you can select No retention configured for child Workflows and Job Definitions as long as you configure retention for the parent Workflow Definition.
If you check Keep Force in the Retention tab for a child Job Definition or Workflow Definition:
- If the sub-Definition has lower retention, the Workflow will display, but you might miss executions that were already purged.
- If the sub-Definitons have a higher retention, they will stay visible for a longer period, but you will not see any relation to the parent Workflow.
Best Practice: Setting Retention at the Highest Level
When you create a Workflow, click its name in the Workflow Editor to display the Workflow Definition Overlay, then set its retention policy on the Retention tab. Setting the retention policy on the Workflow itself automatically applies that retention policy to all Job Calls and sub-Workflows in the Workflow.
Best Practice: Frequently Run Jobs
If you need to schedule a Job to run frequently (for example, every 15 minutes), see if you can make that Job event-based (for example, triggered via a File Event or Web Service). If this is not possible, configure its retention policy as shown below.
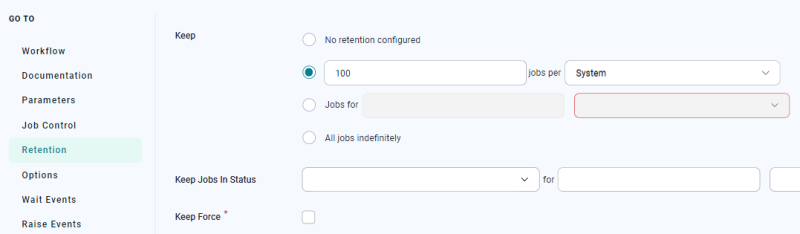
As a base rule, you can set the retention policy for frequently-run Jobs to keep only the last 100 executions. If you start to run many of these Jobs (50 or more), consider lowering this number to keep only ten executions.
If you want to be able to troubleshoot, you can keep Jobs in Error status. The screen shot below shows a scenario wherein completed Jobs are not kept, but errors ARE kept. This is helpful if you want to be able to trace Jobs in a certain status for a longer period of time than the standard status in order to troubleshoot, find trends, and so forth.
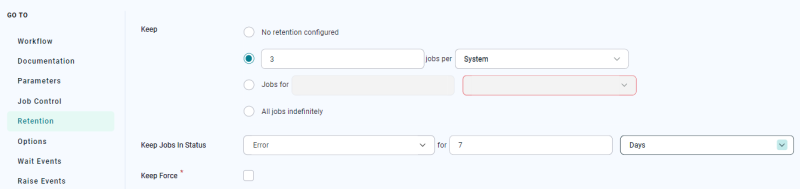
Note: Keep Jobs In Status means Jobs with a given status will not be automatically deleted. Be sure to specify a keep duration, delete the processes manually, or create a script to delete them.
The Jobs per dropdown list can be used to store the specified number of Jobs per System, User or Key. Setting this to something other than System can increase the number of Jobs kept.
Example Retention Configurations
This section gives an overview of common and best-practice retention configurations when you are developing Job and Workflow Definitions.
Note: Data older than three months should be archived and then removed from RunMyJobs, even for lower-frequency Jobs and Workflows.
The table below provides some examples and housekeeping rules to use as a guideline. It shows an ideal retention based on the above three-month statement and general usage, and a best practice retention policy that will be workable in almost all environments.
| Job or Workflow Frequency | Ideal Retention Policy | Best Practice Retention Policy |
|---|---|---|
| Monthly | 3 months | 12 months |
| Weekly | 3 months | 6 months |
| Multiple times per week (less than daily) | 3 months | 3 months |
| Daily | 8 days (using Keep Process in Status to keep error processes for longer) | 1 month |
| 2 runs per day | 8 days (using Keep Process in Status to keep error processes for longer) | 1 month |
| 8 runs per day | 8 days (using Keep Process in Status to keep error processes for longer) | 8 days (using Keep Process in Status to keep error processes for longer) |
| Hourly or less | Last 25 executions | Last 100 executions |
Reviewing Retention Settings
You can review the retention settings of all your processes by navigating to Configure > Automate > Scheduling tools > Retention.
If you set retention at the Workflow level, this screen shows No retention configured. This is because RunMyJobs cannot be sure whether you also submit a Job outside of its Workflow Definition.
You can use the code below to run a RedwoodScript Job Definition. It will do an additional check on the retention policies of parent Workflows. This list should be a lot smaller, and can be used to review retention on your environment. It does assume you run all Jobs without retention policies in Workflows that have retention policies.
It is normal to still see System_ and SAP_ Job Definitions (which are either templates or configuration objects) in this list.
{
String query = "select jd.* from JobDefinition jd where (jd.UniqueId = jd.MasterJobDefinition) and (jd.KeepUnits is StringNull) order by jd.Partition, jd.Name";
for (Iterator it = jcsSession.executeObjectQuery(query, null); it.hasNext();)
{
JobDefinition jd = (JobDefinition)it.next();
if (!parentHasRetention(jd))
{
jcsOut.println(jd.getPartition().getName() + "." + jd.getName());
}
}
}
boolean parentHasRetention(JobDefinition jd)
{
boolean result = false;
String query = "select jcc.* from JobChainCall jcc where (jcc.JobDefinition = ?)";
for (Iterator it = jcsSession.executeObjectQuery(query, new Object [] {jd.getUniqueId()}); it.hasNext();)
{
JobChainCall jcc = (JobChainCall)it.next();
if (jcc.getJobChainStep().getJobChain().getJobDefinition().getKeepUnits() != null)
{
result = true;
break;
}
else
{
result = parentHasRetention(jcc.getJobChainStep().getJobChain().getJobDefinition());
if (result)
{
break;
}
}
}
return result;
}